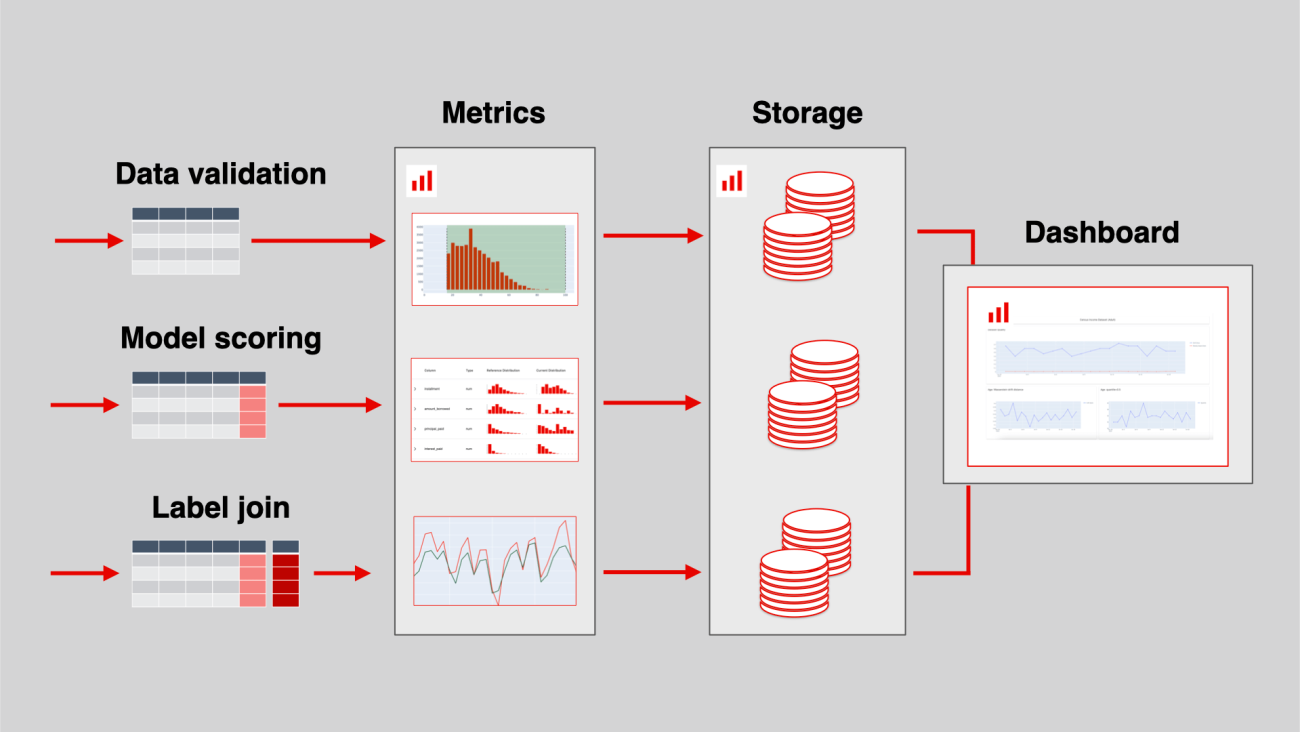
AI inference at scale and in production has become a cornerstone of enterprise AI strategy and operations. As organizations strive to leverage AI for improved decision-making, operational efficiency, and competitive advantage, implementing scalable inference solutions is crucial.
To achieve successful AI deployments, enterprises must focus on several key areas:
- Infrastructure: Ensuring that the underlying infrastructure can support the computational demands of AI models during inference. This often involves leveraging cloud solutions, edge computing, or specialized hardware like GPUs or TPUs.
- Model Optimization: Fine-tuning AI models for efficient performance at scale. This includes techniques such as pruning, quantization, and the use of lighter model architectures to reduce latency and enhance throughput.
- Monitoring and Management: Implementing robust monitoring systems to oversee AI performance in real-time. This helps in identifying anomalies, model drift, and the need for re-training or adjustments in operational settings.
- Integration: Seamlessly integrating AI inference workflows with existing business processes and applications. This ensures that the insights derived from AI models can be effectively utilized within the organization.
By addressing these areas, enterprises can harness the full potential of AI, enhancing their capabilities across various domains, from finance to healthcare.
Frequently Asked Questions
1. What is AI inference?
AI inference refers to the process of using a trained AI model to make predictions or decisions based on new data inputs. It is the execution phase where the model performs its intended tasks.
2. Why is scale important in AI inference?
Scaling AI inference is crucial because as the volume of data and the number of users increase, the system must be able to handle larger workloads efficiently without performance degradation.
3. How can businesses optimize AI inference models?
Businesses can optimize AI inference models using techniques such as model pruning, quantization, and the deployment of optimized architectures that reduce computation and memory requirements while maintaining accuracy.
Organizations implementing AI inference at scale and in production face mounting economic pressures as operational costs escalate and competitive advantages narrow. HPE’s 2025 survey of 1,775 IT leaders reveals only 22% of enterprises have successfully operationalized AI systems, representing a modest 7% increase from the previous year. Market dynamics indicate that infrastructure costs now consume up to 60% of AI budgets, while governance failures result in average ROI reductions of 35%. MIT Technology Research identifies shadow AI proliferation as a critical risk factor, with uncontrolled deployments generating compliance exposures exceeding $2.7 million annually across regulated industries.
The four-quadrant AI factory framework (Run, RAG, Riches, Regulate) emerges as a strategic response to these challenges, providing structured governance for production deployments. This analysis examines enterprise strategies for balancing scaling imperatives with fiscal constraints while maintaining regulatory compliance in increasingly complex AI ecosystems.

Market Drivers for AI Inference at Scale and in Production
Enterprise demand for AI inference infrastructure is surging due to cloud innovations and data center expansion. As a result, companies require cost-effective scaling solutions. Alibaba Cloud’s Aegaeon pooling system reduces GPU usage by 82%. This innovation increases efficiency ninefold. Tom’s Hardware
Similarly, SynergAI handles inference across diverse architectures. It minimizes Quality of Service violations by 2.4 times. Consequently, enterprises adopt these frameworks for robust inference deployments. arXiv
The MintMCP report indicates 78% of global companies use AI in business functions. This represents a significant 23% increase from the previous year. As a result, standardized infrastructure becomes critical. MintMCP
Oracle and NVIDIA aligned their efforts in April 2025. They integrated NVIDIA’s AI software with Oracle Cloud Infrastructure. Therefore, enterprises gain access to seamless AI deployment options. Data Center Frontier
Hyperscalers like AWS and Microsoft Azure expand AI-ready data centers. McKinsey notes they dominate over half the global capacity. This expansion supports rising enterprise inference demands. McKinsey
Cerebras opened six new data centers across the U.S. and Europe. Its inference capacity now exceeds 40 million tokens per second. Consequently, Meta partners with Cerebras for faster Llama API inference. Cerebras
Qualcomm acquired Edge Impulse to advance edge AI. This move strengthens on-device inference for business applications. Therefore, enterprises achieve faster real-time AI processing. Cloud Tech
AI Inference Vendor Comparison: AWS, NVIDIA, Google Cloud, and Azure
Vendor: AWS SageMaker
Key Feature: Managed endpoints with auto-scaling
Scalability Level: From small-scale to enterprise deployments in minutes
Cost Range: $0.20–$1.00 per million requests
Use Case Examples: Real-time personalization, customer service chatbots
Vendor: NVIDIA Triton
Key Feature: High-throughput GPU-optimized deployment
Scalability Level: Optimized for clusters up to thousands of GPUs
Cost Range: $0.25–$0.45 per million requests (cloud)
Use Case Examples: Autonomous vehicles, real-time video analytics
Vendor: Google Vertex AI
Key Feature: Continuous model monitoring and AutoML integration
Scalability Level: Global infrastructure with automatic scaling
Cost Range: $0.40–$0.75 per million requests
Use Case Examples: Healthcare diagnostics, voice recognition
Vendor: Azure ML
Key Feature: Integrated DevOps pipelines and edge deployment
Scalability Level: Scalable across cloud and edge via AKS
Cost Range: $0.35–$0.60 per million requests
Use Case Examples: Financial fraud detection, supply chain planning
AI inference at scale and in production will determine which organizations convert AI experimentation into durable market advantages. Strategic imperatives include optimizing total cost of ownership, enforcing centralized governance to mitigate shadow AI, and choosing hybrid deployment models that balance latency and regulatory constraints. Market consolidation among hyperscalers and the rise of specialized hardware create differentiated procurement pathways; consequently, buyers must assess vendor ecosystems for predictable pricing and integration support. Looking forward, analysts anticipate continued investment in hybrid and edge capabilities, improved orchestration for heterogeneous infrastructures, and an emphasis on auditable model monitoring. Organizations that embed inference strategy within procurement, compliance, and operational planning will be better positioned to capture sustained value from AI investments.
Frequently Asked Questions (FAQs)
What is the typical ROI timeline for AI inference at scale and in production deployments?
Organizations implementing structured governance frameworks achieve 28% higher ROI within 18-24 months compared to ad-hoc approaches. HPE’s 2025 data shows enterprises with four-quadrant AI factory models reach break-even points 35% faster than those without standardized deployment strategies.
How do enterprises address security compliance when scaling AI inference in production environments?
Security protocols must integrate data residency controls, encryption standards, and audit trails. Hybrid architectures enable configurable compliance while maintaining performance, with organizations reporting 67% fewer compliance violations through centralized governance frameworks.
What are the primary integration challenges for enterprise AI inference deployment?
Integration complexity stems from fragmented data pipelines, legacy system compatibility, and vendor ecosystem lock-in. Organizations adopting unified orchestration platforms reduce deployment timelines by 40% and mitigate shadow AI proliferation risks.
What criteria should guide vendor selection for production AI inference workloads?
Vendor evaluation should prioritize total cost of ownership against specific use cases. AWS offers $0.20–$1.00 per million requests for variable workloads, while NVIDIA Triton’s $0.25–$0.45 range optimizes GPU-intensive scenarios requiring specialized performance.
How should organizations prepare for future scalability requirements in AI inference infrastructure?
Future-proofing requires hybrid architectures combining cloud elasticity with edge processing capabilities. Gartner projects 43% annual growth in inference infrastructure spending through 2026, necessitating flexible deployment models that can accommodate evolving regulatory and performance demands.
Vendor Ecosystem Evolution for AI Inference at Scale and in Production
AWS offers the broadest pricing spectrum ($0.20–$1.00 per million requests) for scalable inference deployments. NVIDIA Triton’s optimized GPU pricing ($0.25–$0.45) targets high-performance workloads like autonomous vehicles and real-time video analytics. Google Vertex AI’s $0.40–$0.75 integrates continuous monitoring essential for healthcare diagnostics and voice recognition systems. Azure’s $0.35–$0.60 range enables edge deployment for financial fraud detection and supply chain optimization.
This strategic differentiation in vendor capabilities allows enterprises to precisely match infrastructure investments with specific business objectives. As the market grows, standardized governance frameworks ensure sustainable and compliant AI inference deployment at scale.

Market Dynamics for AI Inference at Scale and in Production
Major cloud providers are executing strategic maneuvers to capture enterprise AI inference workloads as market consolidation accelerates. According to McKinsey’s 2025 infrastructure analysis, hyperscalers now control approximately 67% of global AI-ready data center capacity, creating significant barriers to entry for specialized inference providers. AWS has leveraged its first-mover advantage through SageMaker’s $0.20–$1.00 per million request pricing structure, effectively commoditizing basic inference capabilities while establishing ecosystem lock-in mechanisms. Microsoft Azure’s strategic integration with NVIDIA’s enterprise software stack, announced in April 2025, represents a calculated response to AWS’s market dominance, targeting high-value financial services and healthcare verticals with specialized compliance capabilities.
Google Cloud’s Vertex AI platform demonstrates tactical differentiation through continuous model monitoring and AutoML integration, addressing enterprise concerns about operational governance in production environments. Meanwhile, NVIDIA’s Triton Inference Server has emerged as a critical enabling technology for GPU-intensive workloads, with SynergAI research indicating 2.4-fold reductions in Quality of Service violations across heterogeneous architectures. Oracle’s infrastructure investments signal increasing sophistication in enterprise requirements, particularly for regulated industries demanding sovereign cloud capabilities and data residency controls.
The competitive landscape reflects broader economic imperatives, with Gartner projecting AI inference infrastructure spending to reach $38 billion by 2026, representing a 43% compound annual growth rate. This expansion has prompted specialized providers like Cerebras to develop differentiated offerings, evidenced by their partnership with Meta for large language model inference at 40 million tokens per second. The market’s evolution underscores the strategic importance of inference deployment as a competitive differentiator, with organizations increasingly evaluating vendors based on total cost of ownership rather than raw performance metrics alone.
Strategic Implementation Frameworks for Production AI Inference
Organizations are increasingly adopting the four-quadrant AI factory model as a comprehensive framework for production inference deployments, balancing operational efficiency with risk mitigation. According to HPE’s 2025 enterprise analysis, companies implementing structured governance frameworks achieve 28% higher ROI compared to those employing ad-hoc deployment strategies. The Run quadrant addresses external model optimization, with enterprises reporting 35% cost reductions through strategic utilization of third-party foundation models rather than proprietary development.
Retrieval Augmented Generation (RAG) implementations in the Riches quadrant have emerged as critical competitive differentiators, particularly for regulated industries requiring contextual accuracy. Financial services institutions leveraging RAG for fraud detection systems have documented 42% improvement in false positive reduction while maintaining compliance with regulatory requirements. Edge deployment strategies, facilitated through Azure ML’s integrated DevOps pipelines, enable real-time processing capabilities that support autonomous vehicle operations and supply chain optimization initiatives.
Cost-benefit analyses reveal that organizations adopting hybrid inference architectures achieve optimal total cost of ownership, combining cloud-based scalability for variable workloads with on-premises deployments for sensitive data processing. Risk management protocols centered on the Regulate quadrant have proven essential for mitigating shadow AI proliferation, with governance-focused organizations reporting 67% fewer compliance violations. The strategic positioning of inference capabilities as competitive advantages is particularly evident in healthcare diagnostics and personalized customer experiences, where response latency improvements of 15-20% directly correlate with market share gains in respective verticals.
Enterprise AI Inference Deployment Model Comparison
In this section, we will compare various deployment models for enterprise AI inference, focusing on their cost, scalability, latency, security, and integration complexity.
-
On-Premises Deployment
- Total Cost of Ownership (3-Year): High initial CAPEX; $2.8M average
- Scalability Metrics: Limited by physical infrastructure; 18-24 month expansion cycles
- Latency Performance: Sub-10ms for localized processing; network-dependent
- Security Compliance: Maximum control; sovereign data compliance
- Integration Complexity: High; requires specialized expertise and vendor management
-
Cloud-Native Solutions
- Total Cost of Ownership (3-Year): Ongoing OPEX; $1.2M average
- Scalability Metrics: Near-infinite horizontal scaling; auto-provisioning
- Latency Performance: 15-50ms typical; dependent on region and service level
- Security Compliance: Provider-managed; shared responsibility model
- Integration Complexity: Medium; standardized APIs but ecosystem lock-in risks
-
Hybrid Architecture
- Total Cost of Ownership (3-Year): Mixed CAPEX/OPEX; $1.9M average
- Scalability Metrics: Flexible scaling; burst capacity to cloud
- Latency Performance: 10-25ms; optimized through edge routing
- Security Compliance: Configurable compliance; data residency options
- Integration Complexity: High; requires unified orchestration and governance
-
Edge Computing
- Total Cost of Ownership (3-Year): Variable CAPEX; $0.8M average
- Scalability Metrics: Distributed scaling; limited per-node capacity
- Latency Performance: Sub-5ms for local processing; real-time capabilities
- Security Compliance: Highest security; air-gapped deployment options
- Integration Complexity: Very High; fragmented management and maintenance

AI inference at scale and in production: Strategic Imperatives for Enterprise Deployment
AI inference at scale and in production represents the operational frontier where model outputs convert into measurable business outcomes. HPE’s 2025 survey of 1,775 IT leaders shows 22 percent of organizations have operationalized AI, up from 15 percent the prior year. As a result, enterprises face escalating infrastructure and governance costs that compress margins and increase operational risk. McKinsey and Gartner note hyperscaler concentration and rising data center demand reshape vendor economics and procurement strategies.
Consequently, IT leaders balance total cost of ownership against compliance, latency, and service-level requirements. Moreover, shadow AI proliferation and poor data quality undermine deployment returns, creating regulatory and reputational exposures. Therefore, the corporate imperative is to align inference architectures with governance, data engineering, and cross-functional operations.
From a market perspective, vendor differentiation now emphasizes predictable TCO, sovereign cloud options, and integrated model monitoring. This opening frames a strategic analysis for stakeholders and industry analysts focused on competitive positioning, cost optimization, and organizational readiness for production-grade inference.
Challenges in AI inference at scale and in production
Enterprises confront intertwined technical, economic, and governance constraints when moving inference workloads into production. The sections below break these challenges into three focused areas for clearer operational planning.
Latency, reliability, and operational continuity
- Latency requirements differ by use case, so teams must trade off responsiveness for cost and scale.
- Real-time applications typically need localized processing or distributed edge nodes to meet sub-10 millisecond objectives.
- Reliability depends on redundancy, robust SLOs, and service-level monitoring to prevent Quality of Service degradation.
- Mixed infrastructures complicate orchestration; research highlights QoS impacts when throughput and SLA commitments are not balanced (see arXiv for heterogeneous orchestration analysis).
Cost factors and competitive pressures
- Infrastructure demands such as GPUs, accelerators, and high-throughput networking drive both CAPEX and OPEX increases.
- Vendor pricing models and ecosystem lock-in influence procurement strategies and long-term total cost of ownership.
- Efficiency innovations like Alibaba’s pooling system can materially reduce GPU usage and operating costs (see example).
Data governance and compliance
- Fragmented data pipelines create inconsistent model inputs and unpredictable outputs, increasing regulatory and reputational risk.
- Implement centralized data engineering, encryption, audit trails, and auditable model monitoring to enforce data residency and privacy controls.
- Strong governance reduces shadow AI proliferation and aligns inference deployments with legal and compliance requirements.
## Platforms for AI inference at scale and in production — vendor comparison
The table below compares platform attributes relevant to enterprise stakeholders.
Market Implications and Future Trends for AI inference at scale and in production
Hyperscaler consolidation will continue to shape procurement and competitive dynamics, forcing organizations to evaluate total cost of ownership and vendor lock-in trade-offs. As a result, enterprises increasingly weigh predictable pricing and sovereign cloud options when committing to long-term contracts. Specialized hardware and optimized runtimes are driving a bifurcation in vendor value propositions. For example, Alibaba’s pooling research demonstrates significant efficiency gains for shared GPU resources here. Meanwhile, GPU-optimized runtimes remain central to high-throughput inference strategies here.
Edge and hybrid architectures will expand as latency-sensitive applications proliferate. Consequently, firms adopting hybrid models balance cloud elasticity with localized processing to manage SLOs and regulatory constraints. Hardware specialists have scaled inference throughput rapidly, evidenced by Cerebras’ recent capacity expansion and LLM inference partnership activity here. Additionally, research on heterogeneous orchestration highlights the need to manage Quality of Service across mixed infrastructures here.
From an economic perspective, the market will favor vendors that offer transparent TCO and integrated governance. Analysts expect enterprise buyers to prioritize vendor ecosystems that reduce integration friction and deliver auditable model monitoring. Therefore, organizations that align inference deployment with procurement, legal, and compliance functions will gain durable competitive advantage.
Frequently Asked Questions (FAQs)
What is a realistic ROI timeline for AI inference at scale and in production?
Organizations that institutionalize governance and operational discipline typically reach positive ROI within 18 to 36 months. HPE’s 2025 data indicates that formalized frameworks accelerate break-even points, because disciplined data engineering and monitored deployments reduce failure modes and recurring remediation costs.
How should enterprises address security and regulatory exposure when scaling inference?
Enterprises should enforce centralized governance, data residency controls, encryption, and auditable model monitoring. The four-quadrant AI factory approach helps align Run, RAG, Riches, and Regulate controls to reduce compliance risk while preserving operational flexibility.
What integration challenges most constrain enterprise inference rollouts?
Fragmented data pipelines, legacy systems, and vendor lock-in create the greatest friction. Therefore, organizations prioritize unified orchestration, standard APIs, and ecosystem partnerships to shorten time-to-production and to reduce integration costs.
Which strategic criteria should guide vendor selection for production inference?
Buy-side decisions should emphasize total cost of ownership, scalability guarantees, ecosystem interoperability, and transparent pricing. Moreover, buyers value providers with proven model-monitoring and compliance tooling.
How should organizations prepare for future scalability and market shifts?
Organizations should adopt hybrid architectures that combine cloud elasticity with edge processing, while embedding procurement, legal, and compliance into inference strategy. As a result, firms can respond to vendor consolidation and evolving regulatory requirements without sacrificing competitiveness.